HashMap底层结构与实现原理之——put、get方法
简介
来源:知乎-极光少年
本文内容基于JDK8。
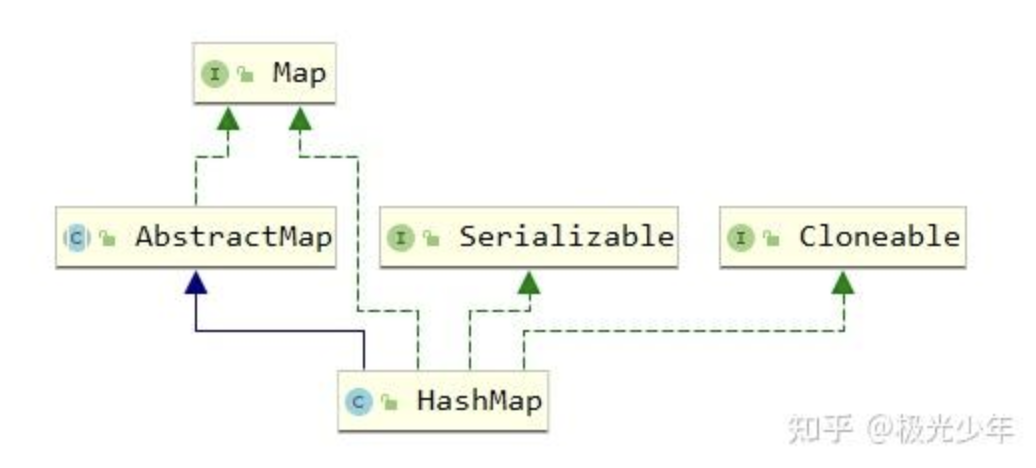
HashMap在java.util包下,它实现了Map接口,实现了Map接口的全部方法。其中最常使用的两个方法为put和get方法。
我们知道,HashMap是用于存储key-value键值对的集合,而key-value键值对结构是基于Map中的Entry接口实现的,所以每一个键值对也可以称为Entry。这些键值对存放在HashMap的一个数组中,这个数组是HashMap的核心部分,数组的每个位置也被称为桶。当然,HashMap的底层结构不止是数组这么简单。
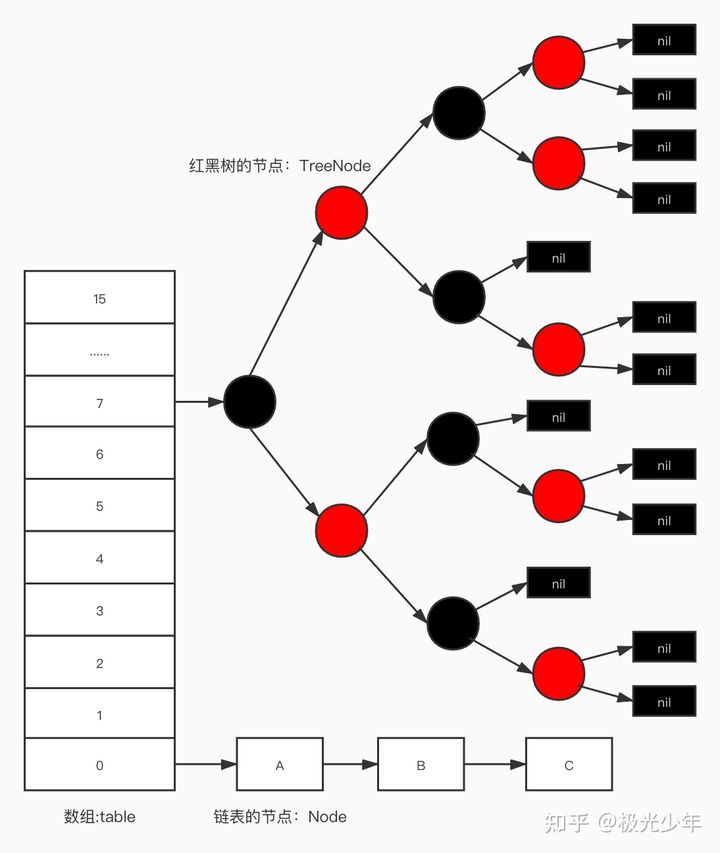
在JDK8之前,HashMap的底层结构是数组+链表的结构,数组的每一个位置存放的是一条链表。从JDK8开始,HashMap的底层结构却变成了数组+链表+红黑树的结构,基本结构如下图所示。
属性
先来看看HashMap中的一些重要属性。
常量:
1.DEFAULT_INITIAL_CAPACITY:默认初始化容量,可以存储元素(Entry)的数量,值为16;
2.MAXIMUM_CAPACITY:最大容量,允许设置的最大存储数量,值为2^30;
3.DEFAULT_LOAD_FACTOR:默认负载因子,用于控制扩容的阈值,值为0.75;
4.TREEIFY_THRESHOLD:链表结构转为红黑树树的阈值,为8,即当链表结构长度达到8时,进行结构转化;
5.UNTREEIFY_THRESHOLD:树结构转为链表的阈值,为6,即当树的节点数达到6时,转化为链表;
6.MIN_TREEIFY_CAPACITY:最小树形化容量阈值,为64,即当HashMap中的元素总数大于64时,才允许将链表转换成红黑树,否则,若桶内元素太多时,则直接扩容,而不是树形化。
变量:
1.size:HashMap中的元素个数;
2.table:Node类型数组,存放元素的容器;
3.entrySet:Entry类型的Set集合;
4.threshold:HashMap的扩容阈值;
5.loadFactor:HashMap负载因子。
数据结构:
Map.Entry<K,V>:是Map接口下的一个内部接口,提供了一些getKey、getValue、setValue等方法。
Node<K,V>:是HashMap下的一个静态内部类,实现了MapEntry接口,是链表的节点类。主要包括两个常量和两个变量:
1.hash:常量,key的hash值,在构造方法中赋值;
2.key:常量,存储的键值对中的键,在构造方法中赋值;
3.value:变量,存储的键值对中的值;
4.next:Node类型,表示连接的下一个节点。
TreeNode<K,V>:链表转为红黑树时的节点数据类型,是HashMap的静态内部类。
以上是HashMap中一些常用的属性和数据结构,我们通过put和get方法来看一下这些属性是使用的。
PUT方法
先来看看源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);·········································①
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;···························································②
if ((p = tab[i = (n - 1) & hash]) == null)·················································③
tab[i] = newNode(hash, key, value, null);··············································④
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;·············································································⑤
else if (p instanceof TreeNode)························································⑥
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);····················⑦
else {
for (int binCount = 0; ; ++binCount) {·············································⑧
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//生成新节点,插入链表尾部
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);·················································⑨
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//发现相同key的节点,跳出循环
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;·····························································⑤//新值覆盖旧值
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();············································································⑩
afterNodeInsertion(evict);
return null;
}
我将源码的重要部分做上了标记,通过一张流程图来帮助我们更好的了解put方法的流程:
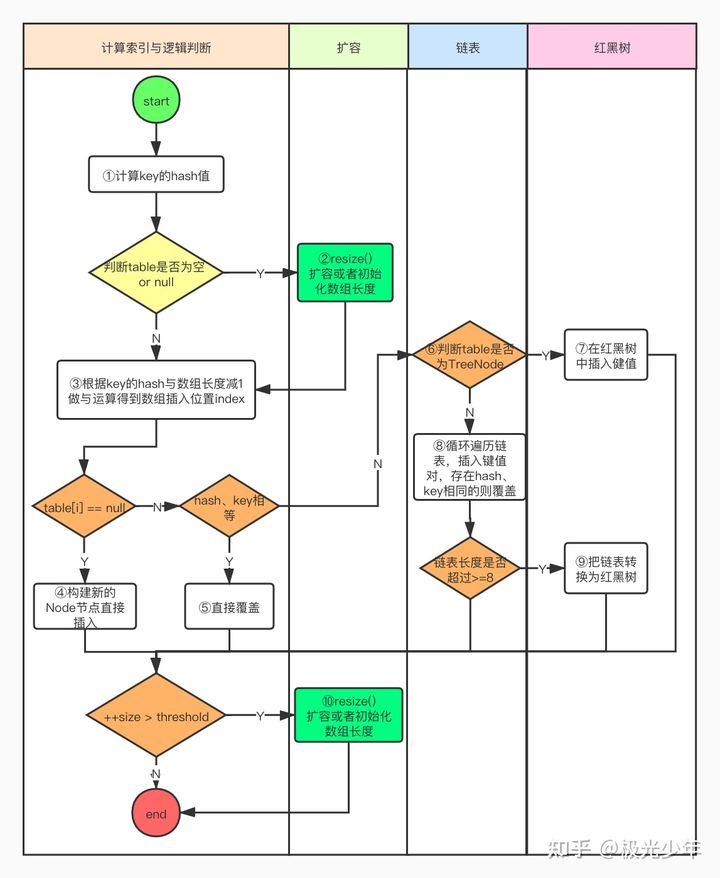
put流程解读:
简述:
1.计算key的hash值,找到对应的数组位置,取出该位置的元素;
2.该元素如果为null,则直接插入Node节点。如果不为null,遍历当前的链表或红黑树;
3.如果有某一个节点的hash、key和要put的hash、key相同,则由插入节点替换该节点;
4.如果遍历结束发现没有相同的key,则生成Node或TreeNode插入末尾;
5.将size++,判断当前size是否超过阈值,如果超过还需进行扩容处理。
详细过程(序号与流程图对应):
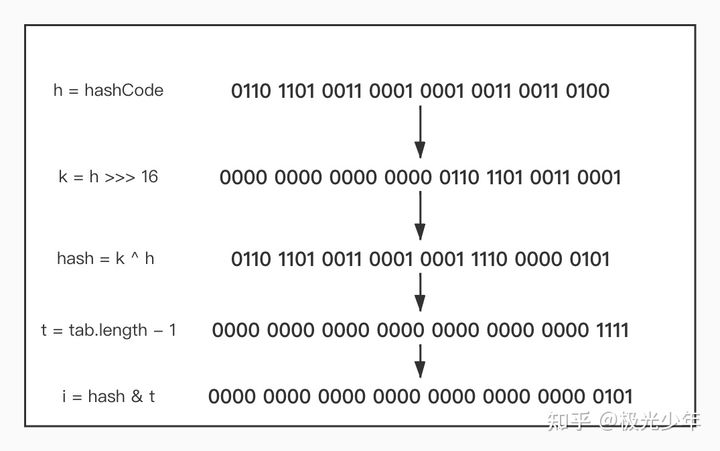
①hash(Object key)方法:根据key值计算hash值。
计算方法:(h = key.hashCode()) ^ (h >>> 16)
这一过程主要是通过调用底层实现的hashCode()方法,生成一个int类型的值,然后与该值的无符号右移16位的结果取异或,最终得到一个hash值。
什么意思呢?
一个int类型的值是二进制32位的。我们假设经过hashCode()方法计算得到一个32位的int类型的值:
0110 1101 0011 0001 0001 0011 0011 0100
对这个值进行无符号右移16位可以得到:
0000 0000 0000 0000 0110 1101 0011 0001
两者取异或,即当两者同位值不同时,结果为1,可以得到:
0110 1101 0011 0001 0001 1110 0000 0101
这就是最终得到的hash值。
②如果HashMap中的数组tab为空,我们需要通过resize()方法对数组进行扩容,如何扩容我们后面再说。
③如果HashMap中的数组tab不为空,则将①中得到的hash值与当前数组长度减1做&运算。
我们假设当前HashMap的数组长度为16,减去1即为15,转为二进制为1111,高位补0得到:
0000 0000 0000 0000 0000 0000 0000 1111
与hash值做&运算可以得到:
0000 0000 0000 0000 0000 0000 0000 0101
可以得到数组的位置为第5位。
④我们将②中得到的数组位置的元素取出,判断该位置的元素是否为空。如果为空,那么直接将hash、key、value封装成链表节点类型,插入当前的数组位置。
⑤如果该位置元素不为空,则要将该元素的hash、key与我们要插入的hash、key作比较是否相同,如果相同,则用我们要插入的value覆盖当前位置的value值即可。
⑥如果key的比较结果不同,此时需要将我们要插入的值连接在当前数组位置上存在的链表或红黑树上了。所以我们要判断当前数组位置上的数据结构是红黑树还是链表。
⑦首先判断该位置的节点是否为红黑树节点,如果是,则以红黑树的方式插入当前节点。
⑧如果不是,则要以链表的方式准备插入。首先遍历当前链表,如果有某个节点的key与插入的key相同,则覆盖该节点;如果没有相同key的节点,则在链表尾部插入新节点。
⑨如果插入后链表长度>=8,则需将链表转换为红黑树结构。
⑩如果此时HashMap的元素总数大于threshold时,会触发扩容,resize(),扩容结束后,整个put的过程也随之结束。如果元素总数不大于threshold时,put过程直接结束。
GET方法
源码:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;··············①
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&························②
(first = tab[(n - 1) & hash]) != null) {································③④
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))·········⑤
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)······································⑥
return ((TreeNode<K,V>)first).getTreeNode(hash, key);···········⑦
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))·····⑧
return e;
} while ((e = e.next) != null);
}
}
return null;
}
我们同样将源码的重要部分做上了标记,通过一张流程图来帮助我们更好的了解get方法的流程:
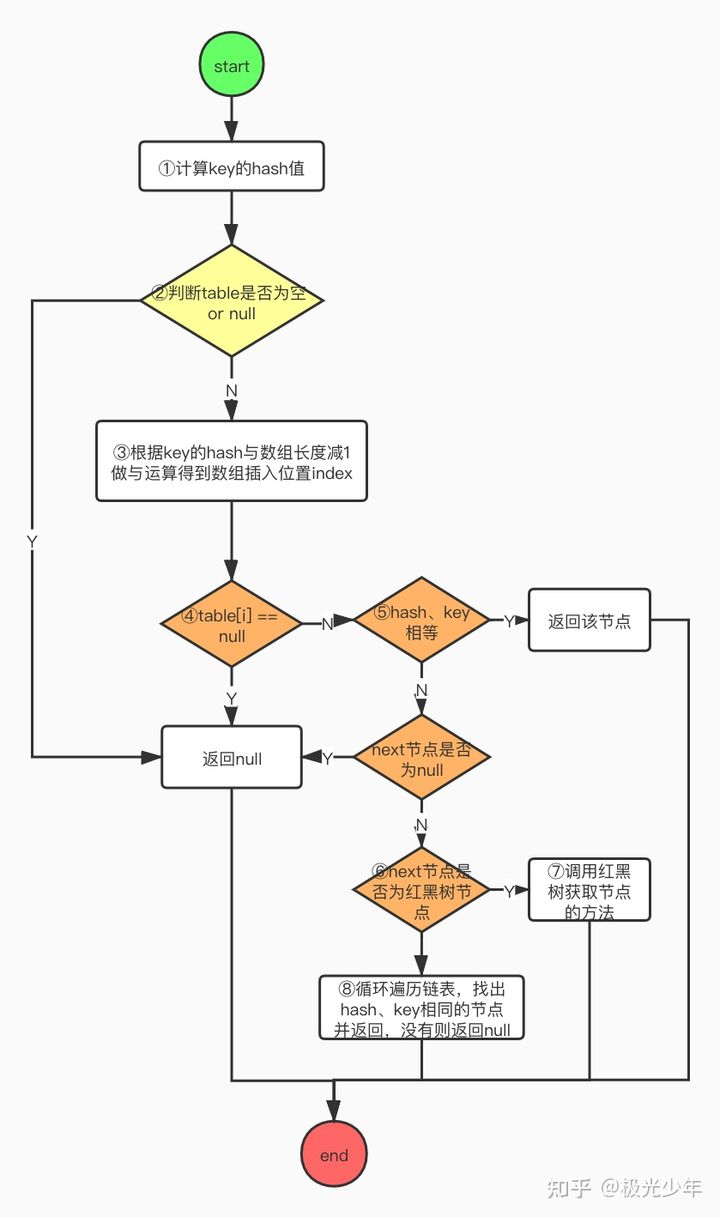
get流程解读:
get方法的流程要比put方法的流程简单许多。
①第一步和put方法一样,获取key的hash值;
②判断数组table是否为空;
③如果数组为空,直接返回null;如果数组不为空,则将hash值与数组长度减1做&运算确定数组位置;
④取出该位置的节点判断是否为空,如果为空,直接返回null,结束查找;
⑤如果不为空,判断当前节点的hash、key与待查找的hash、key是否相等,如果相等返回该节点Value,查找结束;如果不相同则判断当前节点的后继节点是否存在,不存在则直接返回null,结束查找;
⑥若存在则需判断节点类型属于链表节点还是红黑树节点;
⑦如果是红黑树节点则调用红黑树查找方法;
⑧如果是链表节点,则整条遍历链表,找到key和hash值相同的节点则返回Value,没有找到则返回null。