MySQL优化相关
MySQL分层逻辑架构
一. MySQL逻辑分层
首先可以把服务端想象成一个大的容器,里面有四层结构,当一个请求过来后,将会执行这四层,执行一遍后才会返回给想要的结果。
1.连接层
客户端发送一个Select是直接交给连接层来处理,而它的作用就是提供与客户端连接的服务.连接层只是与客户端建立起连接.完成一些类似连接处理,授权认证 及相关的安全方案. 在该层上引入了连接池的概念.
2.服务层
提供核心的服务功能,如sql接口,完成缓存的查询,
sql的分析和优化部分及内置函数的执行.
服务包括以下内容:
2.1Mangement Service
备份 安全 复制 集群
2.2-SQL interface
存储过程 视图 触发器
2.3-Parser解析
查询事务 对象权限
2.4-Optimizer优化器
当编写Sql语句执行时,优化器会觉得我写的sql语句性能不够好,这个时候,优化器会自己写一个等价于跟我写的执行后结果一致的sql语句进行代替.
2.5-Cache Buffers
缓存
服务器会查询内部的缓存,如果缓存空间足够大,这样可以解决大量读操作的环境中,能够很好的提升系统性能
3.引擎层
存储引擎是真正负责MYSQL中数据的存储和提取,服务器通过API与存储引擎进行通信, 不同的存储引擎提供的功能不同,可以根据自己的实际需求来进行选取。
常见的有:lnnoDB、MylSAM、Memory
lnnoDB:它在设计的时候,它是事务优先。
原理:因为它是行锁,每一条数据都要锁,锁的太多,性能就降低了,虽然性能降低了,但是适合高并发了,就不容易出错了。
MylSAM:性能优先
原理:因为它是表锁,对于表里面的十条数据来说是不受影响的,对十条锁一次就完了,所以性能快。
Memroy:memory存储引擎是MySQL中的一类特殊的存储引擎。
其使用存储在内存中的内容来创建表,而且所有数据也放在内存中,因此,其基于内存中的特性,这类表的处理速度会非常快,但是,其数据易丢失,生命周期短。
4.存储层
主要是将数据存储在运行的计算机文件系统之上,并完成与存储引擎的交互。
二. 整体执行流程
1.首先客户端发出一个Select操作
2.连接层接收后给服务层
3.服务层对你的查询进行一个优化,并把优化结果给引擎层
4.选择当前数据库的引擎,选完引擎后,引擎将最终的数据交给了存储层
5.存储层,用存储层来存储数据
MySQL索引
什么是索引?
首先,索引是一种数据结构。排好序的快速查找的数据结构。
在数据之外,数据库系统还维持着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构的基础上实现高级查找算法。这种数据结构,就是索引。
索引的优势
提高检索效率,降低数据库的IO成本
类似图书馆里的图书管理,提高数据的检索效率,降低了io成本。例如:图书管理有100万条藏书,ok,兄弟此时进去找书,如果没有索引,从第一条到到100万条,祖坟冒青烟你牛恰巧第一条就是要找到图书,那么点子背的找到100万条全表扫描。那么这个时候如果频繁进行100万次的IO。不仅浪费时间,而且还消耗内存。如果像上面树的方式大大减少查找时间和IO的频繁。
通过索引列队数据进行排序,降低数据排序的成本,降低了CPU的消耗。
索引的劣势
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表中的记录,所以索引列也是要占空间的。
- 虽然索引大大提高了查询速度,同时会降低更新表的速度。比如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL不仅要保存树,还要保存一下索引文件每次更新添加了索引列的字段。都会调整因为每次更新带来的键值变化后的索引。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间来研究建立最优秀的索引,或者优化查询SQL语句。
磁盘IO与预读
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不仅把当前磁盘地址的数据,而且把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
适合建索引和不适合建索引
哪些情况适合建索引:
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他标关联的字段,外检关联建立索引
- 频繁更新的字段不适合创建索引(更新字段不仅要更新数据本身,而且还要更新索引树)
- where条件里用不到的字段不创建索引
- 单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
- 查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度(索引主要干两件事:检索、排序。)
- 查询中要统计或者分组的字段
哪些情况不适合建索引:
- 表记录太少(300万左右性能开始逐渐下降,虽然官方文档说撑得住5-8百万以上,但是根本也不能等到这个时候再去优化,性能肯定会受到影响)
- 经常增删改的表(为什么?提高了查询速度,同时却会降低了更新表的速度,入队表进行INSERT,UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件)。
- 数据重复切分布平均的表字段,因此应该只为最经常查询和最经常排序的数据建立索引。注意,如果某个数据列包括许多重复的内容,为它建立索引就没有太大的实际效果了。(假设一个表有10万行的记录,有一个字段A只有True和False两个值,且每个值的分布概率大约为50%,那么对这种表的A字段建立索引一般不会提高数据库的查询速度。再比如对银行卡建立索引,毕竟银行卡没有重复的。索引的选择性是指索引列中不同值的数据与表中的记录数的比,如果一个表中有2000条记录,表索引列就有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。一个索引的选择性越接近于1,那么这个索引的效率就越高。)
MySQL索引优化1-性能分析Explain
MySQL自带查询优化器(MySQL Query Optimizer)
- MySQL中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算机分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划(系统认为最优的数据检索方式,不见得是DBA认为是最优的,这部分最耗费时间)
- 当客户端向MySQL请求一条Query,命令解析器模块完成请求分类,区别处是SELECT并转发给MySQL Query Optimizer时,MySQL Query Optimizer 会先对整条Query进行优化,处理吊一些常量表达式的预算,直接换算成常量值,并对Query中的查询条件进行简化和转换,去掉一些无用或显而易见的条件、结构调整等。然后分析Query中的hint信息(如果有),看现实Hint信息是否可以完全确定该Query的执行计划。如果没有Hint或Hint信息不足以完全确定执行计划,则会读取索设计对象的统计信息,根据Query进行写相应的计算分析,然后在得出最后的执行计划。
MySQL常见瓶颈
- CPU:CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据的时候
- IO:磁盘I/O瓶颈发生在装入数据远大于内存容量的时候
- 服务器硬盘的性能瓶颈:top,free,iostat和vmstat来查看系统的性能状态
如果SQL优化器没有更改,并且这些瓶颈也没有出现,那么调出MySQL分析报告来看看到底MySQL哪里惹了事。
EXPLAIN
- 是什么?(查看执行计划)
- 使用Explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
- 能干吗?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
- 怎么用?
- Explain + SQL语句
- 执行计划包含的信息

各字段解释:
id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序。
- 包含3种情况:
- id相同,执行顺序由上至下
- id不同,值越大优先级越高越先被执行
- id部分相同,如果id相同,可认为是同一组,执行顺序从上到下。在所有组中,id值越大执行优先级越高。
总结:id的值表示select子句或表的执行顺序,id相同,执行顺序从上到下,id不同,值越大的执行优先级越高。
- 包含3种情况:
select_type:SELECT的类型
常见:
- SIMPLE : 简单的SELECT查询, 查询中不包含子查询或者UNION
- PRIMARY : 查询中包含任何复杂的子查询, 最外层查询被标记为PRIMARY
- SUBQUERY : 在SELECT或WHERE列表中包含子查询
- DERIVED : 在FROM列表中包含的子查询被标记为DERIVED(衍生), MySQL会递归执行这些子查询, 把结果放在临时表里
- UNION : 若第二个SELECT出现在UNION之后, 则被标记为UNION; 若UNION包含在FROM子句的子查询中, 外层SELECT被标记为 : DERIVED
- UNION RESULT : 从UNION表获取结果的SELECT
table:显示这一行的数据是关于哪张表的
type:访问类型, 显示查询使用了何种类型,
从最好到最差依次是:system > const > eq_ref > ref > range > index > ALL (常见的)
一般来说, 要保证查询至少达到 range 级别, 最好能达到 ref 。
system:表只有一行记录(等于系统表), 这是 const 类型的特例, 平时不会出现
const:表示通过索引一次就找到了, const 用于比较 primary key 或者 unique 索引。因为只匹配一行数据, 索引很快, 如将主键置于where列表中, MySQL就能将该查询转换为一个“常量”。
eq_ref:唯一性索引扫描, 对于每个索引键, 表中只有一条记录与之匹配。常见于主键或唯一索引扫描
ref:非唯一性索引扫描, 返回匹配某个单独值的所有行。本质上也是一种索引访问, 它返回所有匹配某个单独值的行, 可能会找到多个符合条件的行, 所以这个应该属于查找和扫描的混合体
eq_ref和ref:就好比一个班级里面,只有一个班主任和一群学生,t2返回的只有一个记录(就就好比班主任),而col1返回的是所有col1等于ac(所有名字是ac的学生)
range:只检索给定范围的行, 使用一个索引来选择行。key 列显示使用了哪个索引, 一般就是在 where 语句中出现了between, < ,> ,in 等的查询。这种范围索引扫描比全表扫描要好, 因为它只需要开始于索引的某一点, 而结束于另一点, 不用扫描全部索引。
- index:Full Index Scan(全索引扫描), index与ALL的区别为index类型只遍历索引树。这通常比ALL快, 因为索引文件通常比数据文件小。(也就是说,虽然ALL和index都是读全表, 但index是从索引中读取的, 而ALL是从硬盘中读取的)。
- ALL:Full Table Scan(全表扫描), 将遍历全表以找到匹配的行。
possible_keys:可能用到的索引,一个或多个,但不一定被查询实际使用。
key:
- 实际使用的索引, 如果为NULL, 则没有使用索引。(要么没建索引,要么建了索引没用,即索引失效)
- 查询中若使用了覆盖索引, 则该索引仅出现在key列表中
key_len:
- 表示索引中使用的字节数, 可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下, 长度越短越好。(有句话说就是:不给马吃草,又要马儿跑)
- key_len显示的值为索引字段的最大可能长度, 并非实际使用长度, 即 key_len 是根据表定义计算而得, 不是通过表内检索获得的(同样的查询结果,key_len用的越少越好)
ref:显示索引的哪一列被使用了, 如果可能的话, 最好是一个常数。哪些列或常量被用于查找索引列上的值。
rows:根据表统计信息及索引选用情况, 大致估算出找到所需记录所需要读取的行数(表中有多少行被优化器查询)
Extra:包含不适合在其他列中显示但十分重要的额外信息
- Using filesort : 说明MySQL会对数据使用一个外部的索引排序, 而不是按照表内索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为"文件内排序"。
- Using temporary : 同比前者性能更差,使用了临时表保存中间结果, MySQL在对查询结果排序时使用了临时表。常见于排序order by和分组查询group by。
- Using index : 表示相应的SELECT操作中使用了覆盖索引(Covering Index), 避免了访问表的数据行, 效率还可以
- Using where : 使用了where过滤
- Using join buffer : 使用了连接缓存索引优化MIN/MAx操作或者对于MyIsam存储引擎优化COUNT(*)操作, 不必等到执行阶段再进行计算, 查询执行计划生成阶段即完成优化。
- Impossible WHERE : where子句值总是false, 不能用来获取任何数据, 如name=‘张三’ and name=‘李四’(不可能一个人名字是张三,又是李四吧)
- Select tables optimized away : 在没有group by子句的情况下, 基于distinct : 优化distinct操作, 在找到第一匹配的元组后即停止找同样值的动作
补充
覆盖索引(Covering Index),一说为索引覆盖
理解方式一:就是select的数据列只用从索引中就能够获取,不比读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。(也就是说建的索引是col1,col2,col3的复合索引,刚好查询的也是这几列或者部分满足)
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的行,因此它不必读取整个行,毕竟索引叶子节点存储了他们所引用的数据,当能通过读取索引就可以得到想要的数据,那就不需要读取行了,一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。
注意:如果使用覆盖索引,一定要注意select列表中只要所需的列,不可 select * ;因为如果将所有的字段一起做索引会导致索引文件过大,查询性能下降。
MySQL索引优化2-优化法则
全值匹配我最爱(怎么建就怎么用)
最佳左前缀法则:如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描厨
存储引擎不能使用索引中范围条件右边的列
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
MySQL在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
is null ,is not null也无法使用索引
like以通配符开头('%abc...')MySQL索引失效会变成全表扫描的操作(like % 加右边)
问题:解决like '%字符串%'时索引不被使用的方法? —— 覆盖索引(索引的个数和顺序与查询的字段完全相同或者部分相同)
字符串不加单引号索引失效
少用or,用它来连接时会索引失效
口诀:
全值匹配我最爱,最左前缀要遵守; 带头大哥不能死,中间兄弟不能断; 索引列上少计算,范围之后全失效; LIKE百分写最右,覆盖索引不写星; 不等空值还有or,索引失效要少用; VAR引号不可丢,SQL高级也不难!
例子:
Sql 语句中 IN 和 EXISTS 的区别及应用
student表
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`stuid` varchar(16) NOT NULL COMMENT '学号',
`stunm` varchar(20) NOT NULL COMMENT '学生姓名',
PRIMARY KEY (`stuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES ('1001', '张三');
INSERT INTO `student` VALUES ('1002', '李四');
INSERT INTO `student` VALUES ('1003', '赵二');
INSERT INTO `student` VALUES ('1004', '王五');
INSERT INTO `student` VALUES ('1005', '刘青');
INSERT INTO `student` VALUES ('1006', '周明');
INSERT INTO `student` VALUES ('1007', '吴七');
score表
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`stuid` varchar(16) NOT NULL,
`courseno` varchar(20) NOT NULL,
`scores` float DEFAULT NULL,
PRIMARY KEY (`stuid`,`courseno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES ('1001', 'C001', '67');
INSERT INTO `score` VALUES ('1001', 'C002', '87');
INSERT INTO `score` VALUES ('1001', 'C003', '83');
INSERT INTO `score` VALUES ('1001', 'C004', '88');
INSERT INTO `score` VALUES ('1001', 'C005', '77');
INSERT INTO `score` VALUES ('1001', 'C006', '77');
INSERT INTO `score` VALUES ('1002', 'C001', '68');
INSERT INTO `score` VALUES ('1002', 'C002', '88');
INSERT INTO `score` VALUES ('1002', 'C003', '84');
INSERT INTO `score` VALUES ('1002', 'C004', '89');
INSERT INTO `score` VALUES ('1002', 'C005', '78');
INSERT INTO `score` VALUES ('1002', 'C006', '78');
INSERT INTO `score` VALUES ('1003', 'C001', '69');
INSERT INTO `score` VALUES ('1003', 'C002', '89');
INSERT INTO `score` VALUES ('1003', 'C003', '85');
INSERT INTO `score` VALUES ('1003', 'C004', '90');
INSERT INTO `score` VALUES ('1003', 'C005', '79');
INSERT INTO `score` VALUES ('1003', 'C006', '79');
INSERT INTO `score` VALUES ('1004', 'C001', '70');
INSERT INTO `score` VALUES ('1004', 'C002', '90');
INSERT INTO `score` VALUES ('1004', 'C003', '86');
INSERT INTO `score` VALUES ('1004', 'C004', '91');
INSERT INTO `score` VALUES ('1004', 'C005', '80');
INSERT INTO `score` VALUES ('1004', 'C006', '80');
INSERT INTO `score` VALUES ('1005', 'C001', '71');
INSERT INTO `score` VALUES ('1005', 'C002', '91');
INSERT INTO `score` VALUES ('1005', 'C003', '87');
INSERT INTO `score` VALUES ('1005', 'C004', '92');
INSERT INTO `score` VALUES ('1005', 'C005', '81');
INSERT INTO `score` VALUES ('1005', 'C006', '81');
INSERT INTO `score` VALUES ('1006', 'C001', '72');
INSERT INTO `score` VALUES ('1006', 'C002', '92');
INSERT INTO `score` VALUES ('1006', 'C003', '88');
INSERT INTO `score` VALUES ('1006', 'C004', '93');
INSERT INTO `score` VALUES ('1006', 'C005', '82');
INSERT INTO `score` VALUES ('1006', 'C006', '82');
course表
DROP TABLE IF EXISTS `courses`;
CREATE TABLE `courses` (
`courseno` varchar(20) NOT NULL,
`coursenm` varchar(100) NOT NULL,
PRIMARY KEY (`courseno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='课程表';
-- ----------------------------
-- Records of courses
-- ----------------------------
INSERT INTO `courses` VALUES ('C001', '大学语文');
INSERT INTO `courses` VALUES ('C002', '新视野英语');
INSERT INTO `courses` VALUES ('C003', '离散数学');
INSERT INTO `courses` VALUES ('C004', '概率论与数理统计');
INSERT INTO `courses` VALUES ('C005', '线性代数');
INSERT INTO `courses` VALUES ('C006', '高等数学(一)');
INSERT INTO `courses` VALUES ('C007', '高等数学(二)');
补充:SQL语句执行顺序详见:SQL语句执行顺序
IN 语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
具体sql示例:
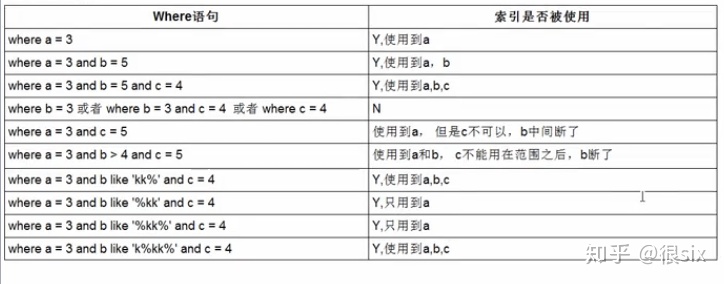
select * from student s where s.stuid in(select stuid from score ss where ss.stuid = s.stuid)
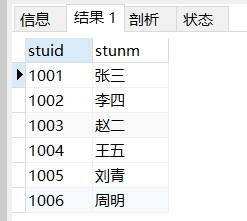
select * from student s where s.stuid in(select stuid from score ss where ss.stuid <1005)
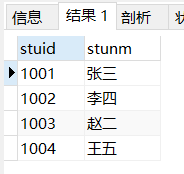
以上两个语句的执行流程:
首先会执行from语句找出student表,然后执行 in 里面的子查询,再然后将查询到的结果和原有的user表做一个笛卡尔积,再根据的 student.stuid IN score.stuid 的条件,将结果进行筛选(既比较stuid列的值是否相等,将不相等的删除)。最后得到符合条件的数据。
EXISTS语句:执行student.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
EXISTS 语法:
SELECT ... FROM table WHERE EXISTS(subquery)
理解:将主查询的数据放到子查询中做条件验证,根据验证结果(TRUE或者FALSE)来决定朱查询的数据结果是否得意保留。相当于从表A和B中取出交集,然后再从A表中取出所在交集的部分数据,当然后面加WHERE条件还可以进一步筛选。
select * from student s where EXISTS(select stuid from score ss where ss.stuid = s.stuid)
这条sql语句的执行结果和上面的in的第一条执行结果是一样的。
但是,不一样的是它们的执行流程完全不一样:
使用exists关键字进行查询的时候,首先,先查询的不是子查询的内容,而是查的主查询的表,也就是说,先执行的sql语句是:
select * from student s
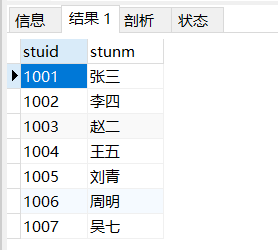
如果成立则返回true不成立则返回false。如果返回的是true的话,则该行结果保留,如果返回的是false的话,则删除该行,最后将得到的结果返回。
IN和EXISTS的区别及应用场景
如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用 in , 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用 exists 。其实区分 in 和 exists 主要是造成了驱动顺序的改变(这是性能变化的关键),如果是 exists ,那么以外层表为驱动表,先被访问,如果是 in ,那么先执行子查询,所以会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外 in 时不对NULL进行处理。
in 是把外表和内表作 hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
查询优化
1.原则
1.小表驱动大表,即小的数据集驱动大的数据集。
数据库最伤神的就是跟程序链接释放,第一个建立了10000次链接,第二个建立了50次。假设链接了两次,每次做上百万次的数据集查询,查完就走,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,这样系统就受不了了。 这时候就诞生了in 和exists的对比。
in
这里假设A表代表员工表,B表代表部门表。 假设部门只有三个,销售、技术部、行政部,言下之意是在这三个部门里的所有员工都查出。
select * from A where id in (select id from B);
等价于:
先循环
for select id from B
比如一个公司有5个部门,但是华为的员工少说有15W-20W,员工总不能比部门多吧,1个员工不能有10-20几个部门吧,这时候就相当于得到了小表(部门表);
后循环:
for select * from A where A.id = B.id
相当于A.id等B表里面的,相当于从部门表获得对应的id。
当B表的数据集必须小于A表的数据集时,用in优于exists。 反之
select * from A where exists (select 1 from B where B.id = A.id);
# 这里的select 1并不绝对,可以写为select 'X'或者'A','B','C'都可以,只要是常量就可以。
等价于:
先循环
for select * from A
后循环
for select * from B where B.id = A.id
这样exists就会变成看看A表是否存在于(select 1 from B where B.id = A.id)里面,这个查询返回的是TRUE或者FALSE的BOOL值,简单来说就是要当A表的数据集小于B表的数据集时,用exists优于in。
要注意的是:A表与B表的ID字段应该建立索引。
EXISTS
语法:EXISTS
SELECT ... FROM table WHERE EXISTS(subquery)。
理解:将主查询的数据放到子查询中做条件验证,根据验证结果(TRUE或者FALSE)来决定朱查询的数据结果是否得意保留。
相当于从表A和B中取出交集,然后再从A表中取出所在交集的部分数据,当然后面加WHERE条件还可以进一步筛选。
补充:
SQL语句执行顺序详见:SQL语句执行顺序
- EXISTS(subquery)只返回TRUE或者FALSE,因此子查询中的SELECT * 也可以是SELECT 1 或者SELECT 'X',官方说法是实际执行时会忽略SELECT清单,因此没有区别。
- EXISTS子查询的实际执行过程可能经过了优化而不是理解上的逐条对比,如果担忧效率问题,可进行实际校验。
- EXISTS子查询旺旺可以用条件表达式,其他子查询或者JOIN来替代,何种最优需要具体问题具体分析。
如果查询的两个表大小相当,那么用in和exists差别不大。
延伸举例巩固:
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in: 例如:表A(小表),表B(大表)
select * from A where cc in (select cc from B) ; # 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) ; # 效率高,用到了B表上cc列的索引。
相反的
select * from B where cc in (select cc from A) ; # 效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) ; # 效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
例:

2.Order By关键字优化
Order By子句,尽量使用Index方式排序,避免使用FileSort方式排序 。
尽可能在索引列上完成排序操作,遵照索引的最佳左前缀。
提高Order By的速度:
Order by时, select * 是一个大忌,应该只 select 需要的字段,这点非常重要。在这里的影响是:
当Query的字段大小总和小于max_length_for_sort_data而且排序字段不是TEXT 或者 BLOB类型时,会用改进后的算法——单路排序,否则用老算法——多路排序。
两种排序算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次IO,但是用单路排序算法的风险会更大一些,所以需要提高sort_buffer_size。
尝试提高 sort_buffer_size (排序缓冲区大小)
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。
尝试提高 max_length_for_sort_data (排序数据的最大长度)
提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高磁盘I/O活动和低CPU使用率。

3.Group By关键字优化
与Order By相似。
group by实质是先排序后进行分组,遵照索引建的最佳左前缀。
当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置。
where高于having,能写在where限定的条件就不要去having限定了。
2.流程
- 慢查询的开启并捕获
- explain + 慢SQL分析
- show profile 查询SQL在MySQL服务器里面的执行细节和生命周期情况
- SQL数据库服务器的参数调优。
慢查询日志
1.说明
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具 体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
具体指运行时间超过Iong_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行时间大于10秒的语句。
由它来查看哪些SQL超出了的最大忍耐时间值,再结合 explain 进行全面分析。
2.使用
默认MySQL没有开启慢查询,需要说动设置这个参数。当然,如果不是调优需要的话,一般不建议开启该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志写入文件。
查看是否开启 SHOW GLOBAL VARIABLES LIKE 'slow_query_log%'。

上面查询结果第一行,这里是开启的,第二行是默认查询路径文件名。
补充:如果通过终端命令设定的话,再查询是看不到修改结果的,需要新开启一个窗口查看即可。如果要永久生效,必须修改my.cnf配置文件(其他系统变量也是如此)。
要明确指定初始慢查询日志状态,请使用 SET GLOBAL slow_query_log = 1 | 0。
使用`SET GLOBAL slow_query_log = 1开启慢查询日志只对当前数据库生效,MySQL重启后便会失效。
那么开启了慢日志后,怎么样的SQL才会记录到慢查询当中呢?
这个是由参数long_query_time控制,默认情况下long_query_time的值是10秒。
查看:SHOW GLOBAL VARIABLES LIKE 'long_query_time';
假如SQL运行时间刚好等于long_query_time的情况,并不会被记录下来,也就是说,在MySQL源码里是判断大于long_query_time,而非大于等于。
设置:SET GLOBAL long_query_time = 3。
记录慢SQL并后续分析:select sleep(4);

1598601396920 查看当前系统中多少条满记录:
show global status like '%Slow_queries%';
配置版
show_query_log = 1;
show_query_log_file=/var/lib/MySQL/MySQL_slow.log
log_query_time=3;
log_output=FILE3.日志分析工具MySQLdumpslow
在生产环境中,如果要手动分析日志,查找、分析SQL,显然是一个体力活,MySQL提供了日志分析工具MySQLdumpslow。
上面测试的慢查询SQL只有一条,假如在实际的生产环境中,慢查询SQL远远高于测试的数量,十几条甚至几十条,假如几条慢查询出现的频率很高,能做到根据轻重优先级来分析并排除那是不是更好?那么就用到了MySQLdumpslow。
[root@lig MySQL]# MySQLdumpslow --help ----------------------------------------------//执行命令
Usage: MySQLdumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using MySQL.server startup script)
-l don't subtract lock time from total times:表示按照何种方式排序
c:访问次数
i:锁定时间
r:返回记录
t:查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
t:即为返回前面多少条数据
g:后边搭配一个正则匹配模式,大小写不敏感
例:
MySQLdumpslow -s r -t 10 /data/MySQL/MySQL-slow.log //得到返回记录集最多的10个SQL
MySQLdumpslow -s c -t 10 /data/MySQL/MySQL-slow.log //得到访问次数最多的10个SQL
MySQLdumpslow -s t -t 10 -g "left join" /data/MySQL/MySQL-slow.log //得到按照时间排序的前10条里面含有做了连接的查询SQL
MySQLdumpslow -s r -t 10 /data/MySQL/MySQL-slow.log | more //另外建议在使用这些命令时结合|和more使用,否则有可能出现爆屏情况MySQL查询优化(3)-show profile
如果想要进行SQL查询的数据调优、排查。
第一步,一定要让出现的问题重现啊(运营工程师或DBA他们从监控系统里面,收到了爆炸,系统变慢了,大家都知道,重要的核心系统都会有另外一套辅助的系统来监控,这种监控系统,比如说现在这个系统慢与每一个模块平均时间,可能5秒钟就能执行完,但是已经长达20秒了,这个时候就要判断为什么慢了。
有很多种可能的原因:可能是程序的内存泄漏,可能是死锁,可能是网络,可能是SQL写的烂。
假设是SQL的问题,那么需要把有问题的SQL抓出来
执行过程:
- 收到问题,诊断SQL
- 开启慢查询日志,抓出执行的慢的SQL
- 使用explain分析(基本上可以找到为题所在,但是如果还是没有摆平,SQL在传输、网络、连接、死锁,需要进一步细粒度的查询和排查的时候就需要使用show profile)
- show profile(还是解决的一般般)
- 配合DBA 到my.cnf配置文件中对各种性能的参数调优和修改(基本上是DBA修改)
show profile
是什么:是mysql 提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量。(默认情况下,参数处于关闭状态,并保存最近15次的运行结果)
分析步骤:
是否支持,看看当前的MySQL版本是否支持:
show variables like 'profiling'; #或 show variables like 'profiling%';
开启功能,默认是关闭,使用前需要开启:
set profiling = on;
运行sql
随便运行几条SQL,以便于show prifiles的日志分析。
查询结果
show profiles;
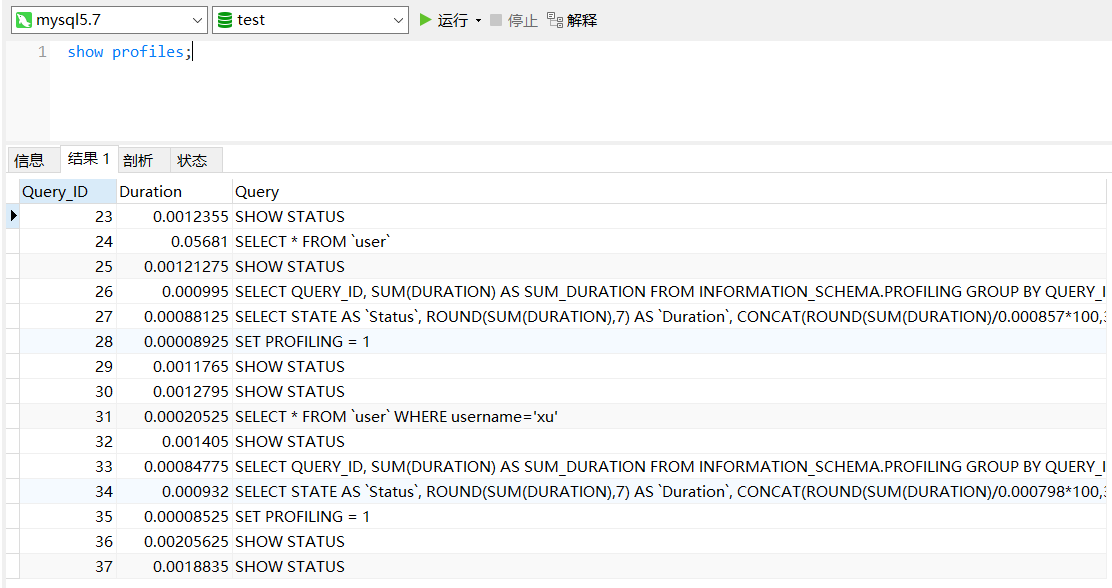
诊断SQL
show profile cpu, block io for query [上一步的Query_ID];
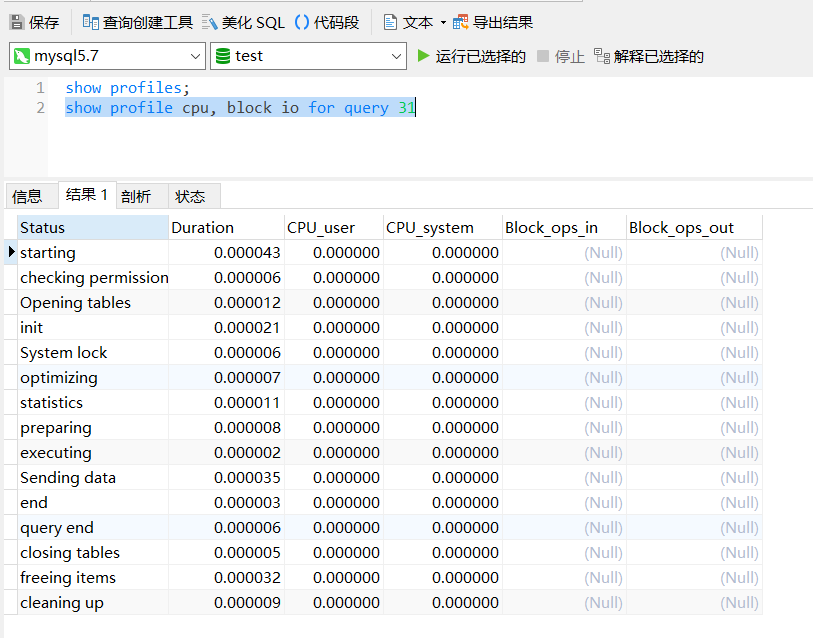
从图中可以看到开始,打开表,加载,关闭表,释放资源、记录日志,清理工作,在这儿可以看到一条SQL执行的完整生命周期。

开发中需要注意的问题
如果
show profile ... for query [Query_ID];出现了如下四个,则必须优化这条sql。- converting HEAP to MyISAM : 查询结果太大, 内存都不够用了,会往磁盘上搬了
- Creating tmp table : 创建临时表
- 拷贝数据到临时表: 假设要查询两百万数据,刚好匹配的条件有一百万,恰巧要把这一百万的数据拷贝到临时表,然后再把数据推送给用户,最后再把临时表删掉,这种情况就是导致SQL变慢的罪魁祸首
- 用完再删除
- Copying to tmp table on disk : 把内存中临时表复制到磁盘
- locked
MySQL查询优化(4)-全局查询日志
show profile可以帮记录下来了后台执行过得SQL,全局查询日志有时也能帮助来调SQL。但是,切记,这个全局查询日志只能在测试环境使用,绝不可以在生产环境使用(公司中一般都是生产环境、测试环境分离,但是测试环境一般都不如生产环境,或多或少会有些差距,但是大部分的SQL正常来说在部到生产之前会在测试上先跑一遍甚至几遍)。
切记:永远不要再生产环境开启全局查询日志这个功能。
配置方式启用:
在MySQL的配置文件中,配置如下:
#开启
general_log=1
#记录日志文件的路径
general_log_file=/path/logfile
#输出格式
log_output=file
命令方式启用:
set global general_log=1; #开启后会把所有的SQL进行记录
set global log_output='TABLE';
此后所编写的SQL语句,将会记录到MySQL库里的general_log表,可以用下面的命令查看。
select * from mysql.general_log;
如果需要做系统的定案分析(如:今天下午2点-3点出现的故障),如果要观察和复现的话,可以在测试环境下模拟一遍,然后把所有的问题复现一下。
然后用general_log这个表来查看什么时间段发生了什么样的SQL,帮助定位问题。
MySQL锁机制
概述
锁是计算机协调多个进程或线程并发访问某一资源的机制(说白了就是防止争抢)。
打个比方,在淘宝上买一件商品,商品只有一个库存,这个时候如果还有另一个人购买,那么如何解决是你买到还是另一个人买到的问题? 这里肯定要用到事务,先从库存表中取出物品数量,然后插入订单,付款后插入付款表信息,然后更新商品数量,在这个过程中,使用锁可以对有限的资源进行保护,解决隔离和并发的矛盾。
在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用意外,数据也是一种供 许多用户共享的资源,如何保证数据并发访问的一致性,有效性是所有数据库必须解决的一个问题。锁充足也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言闲的尤其重要,也更加复杂。
锁的分类
- 从对数据操作的类型(读/写)分
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
从对数据操作的粒度分(表锁、行锁)
开销、加锁速度、死锁、粒度、并发性能,只能就具体应用的特点来说哪种锁更合适
1.表锁(偏读)
偏向MyISAM存储引擎,开销小,加锁块;无死锁;锁定颗粒大,发生锁冲突的概率最高,并发度最低。
开玩笑的说,早上来上班你第一个来的, 到公司就把大门给锁住了,把门禁电关了,整个公司现在你一个人独享,别人还能跟你冲突吗,并发度也就最低了。
1.案例分析(加读锁)
- 建表SQL
mysql> create table mylock(
-> id int not nul primary key auto_increment,
-> name varchar(20)
-> )engine myisam;
insert into mylock(name) values ('a');
insert into mylock(name) values ('b');
insert into mylock(name) values ('c');
insert into mylock(name) values ('d');
insert into mylock(name) values ('e');
select * from mylock;
加锁和解锁命令:
lock table 表名1 read|write, 表名2 read|write; #加锁
unlock tables; #解锁
- 加读锁(共享锁)
lock table mylock read;
查看表上的锁:官方文档-show open tables
show open tables;
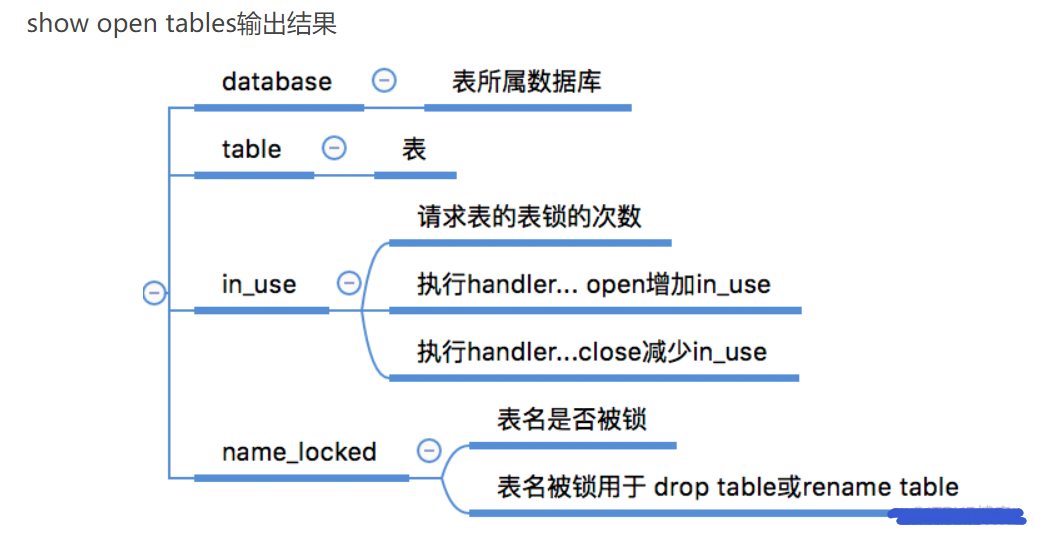
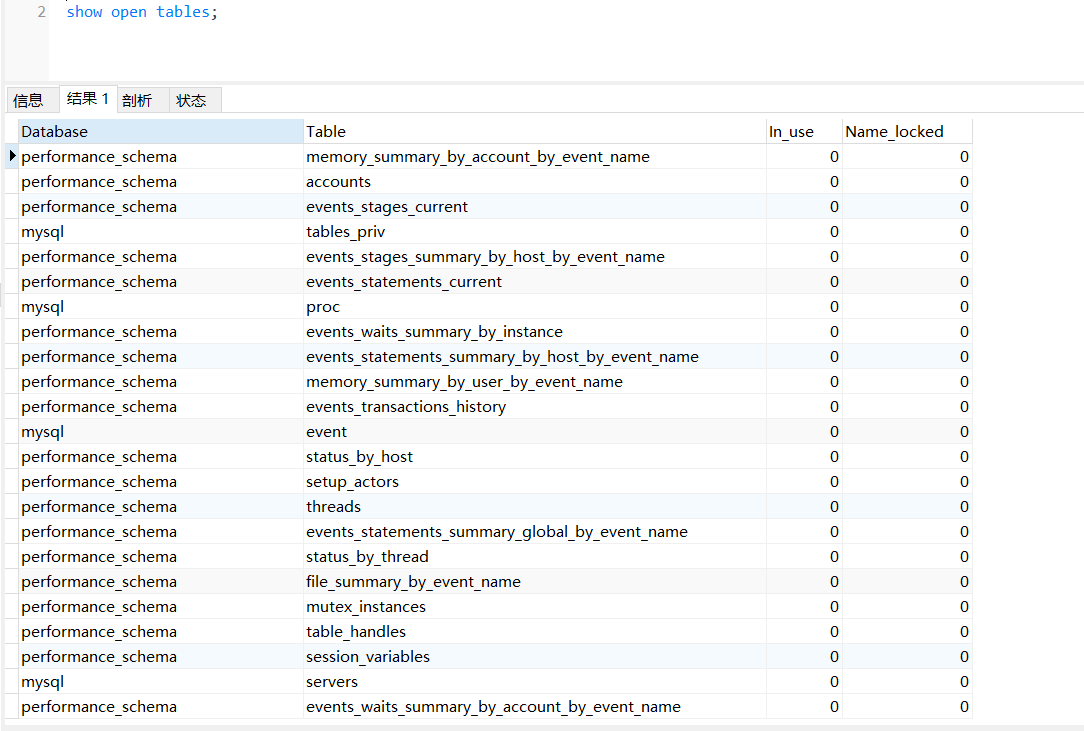
加读锁后,读取自己可以,写自己以及读取本库中别的表都不可以,言下之意就是只要加了读锁,就必须要把这笔读的账清掉再去做别的事。
总结
(窗口1)获得表mylock的read锁定时:
- 当前session(窗口1)可以进行查看该表记录操作;其它session也可查该表记录
- 当前session不能查看其它没有锁定的表(账没结);其它session可以查询或更新其它非锁定的表
- 当前session插入或更新锁定表都会提示报错;其它session插入或更新锁定表都会一直阻塞等待获取表
- 当前session释放读锁时,其它session获得锁,执行插入或更新完成。
2.案例分析2(加写锁)
当session1(窗口1)获得表mylock的write锁定时:
- 当前session1对锁定都得表进行查询、更新操作都可以执行,其它session对锁定表的查询(更新操作也一样)被阻塞,需要等待锁被释放。(如果可以,请换成不同的id来进行测试,因为mysq有缓存,查询的多了,第二次的条件会从缓存获得,会影响锁效果演示)
- 当前sesison1释放锁,其它session获得锁,查询返回。
案例结论
MyISAM在执行查询(SELECT)前,会自动给涉及查询(SELECT)的所有表加读锁,在执行增删改操作前,会自动给涉及增删改操作的表加写锁。
MySQL的表级结构有两种模式:
表共享读锁(Table Read Lock)
表独占写锁(Table Write Lock)

结论:
对MyISAM引擎的表进行操作,会有以下情况:
- 对MyISAM表的读操作(加读锁),不会影响其他进行对同一表的读操作,但会阻塞同一表的写操作,只有当读锁释放后,才会执行其它进程的写操作。
- 对MyISAM表的写操作(加写锁),会阻塞其它进行对统一读和写操作,只有当锁释放后,才会执行其它进程的读写操作。
简而简之,就是:读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
补充:
如何分析表锁定
可以通过查看table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定。
SQL:
show status like 'table%';
这里会有几个变量来记录MySQL内部表级锁定的情况,其中最重要的两个变量说明如下:
Table_locks_immediate:产生表级锁定的次数,表示可以立即获取所的查询次数,每立即获取锁值Table_locks_waited:出现表级锁定征用而发生等待的次数(不能立即获取所的次数,每等待一次锁值加1),此值高则说明存在着较严重的表级锁征用情况。
此外,MyISAM的读写锁调度是写优先,所以MyISAM不适合做写为主的表的引擎,因为加写锁后,其它线程不能做任何操作,大量的更新会使查询难得到锁,从而造成永远阻塞。
2.行锁(偏写)
行锁(偏向InnoDB存储引擎,开销大, 加锁慢,会出现死锁;锁定粒度最小,发生锁冲突的概率最低(假设100行,你用45行我用78行,两者无交集),并发度也最高。
InnoDB与MyISAM的最大不同的两点:
- 支持事务(TRANSACTION);
- 采用了行级锁;
回顾:
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(lsolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务处理带来的问题:
更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题——最后的更新覆盖了由其他事务所做的更新。
脏读(Dirty Reads):事务A读取到了事务B已修改但尚未提交的的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。
不可重复读(Non-Repeatable Reads):事务A读取到了事务B已经提交的修改数据,不符合隔离性。
幻读(Phantom Reads):事务A读取到了事务B提交的新增数据,不符合隔离性。
脏读是事务B里面修改了数据,幻读是事务B里面新增了数据。
事务隔离级别:

案例分析
- 建表SQL
CREATE TABLE test_innodb_lock (
a int(11),
b varchar(16)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test_innodb_lock valeus(1,'b2');
insert into test_innodb_lock valeus(3,'3');
insert into test_innodb_lock valeus(4,'4000');
insert into test_innodb_lock valeus(5,'5000');
insert into test_innodb_lock valeus(6,'6000');
insert into test_innodb_lock valeus(7,'7000');
insert into test_innodb_lock valeus(8,'8000');
insert into test_innodb_lock valeus(9,'9000');
insert into test_innodb_lock valeus(1,'b1');
create index test_innodb_a_ind on test_innodb_lock(a);
create index test_innodb_lock_b_ind on test_innodb_lock(b);
select * from test_innodb_lock;
行锁演示
MySQL5.5以后默认存储引擎为InnoDB,MySQL默认的数据提交操作模式是自动提交模式(autocommit),这就表示除非显式地开始一个事务,否则每个查询都被当做一个单独的事务自动执行。
show variables like "autocommit"; #查看自动提交状态 set autocommit=0; #关闭自动提交
总结
创建两个会话,先关闭 autocommit;(set autocommit=0)
- session1执行更新操作,没有手写commit;session2执行同一行数据的更新操作,会被阻塞。
- session1提交commit更新;session2解除阻塞,更新正常进行。
- session1与session2执行不同行的更新操作时,互不影响,不会发生等待阻塞情况
- 两者提交,数据显示正常。
索引失效行锁变表锁
首先知道如果索引失效的情况下,那么肯定会导致索引失效,但是如果使用不当,会导致行锁变成表锁。
上文中数据库的存储引擎为InnoDB,并且关闭了自动提交,在创建表的时候创建了两个索引,分别在表中的a和b字段上建立了两个单值索引。如下

看一下表信息
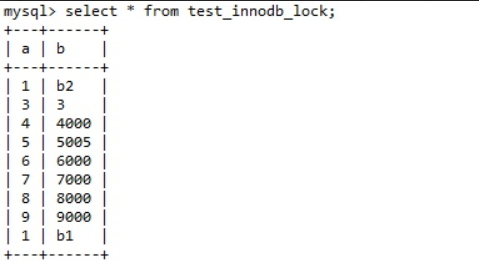
其中,a为int型,b为varchar型
上文中说过,两个会话去执行不同的记录各不相干不会导致阻塞状态。
在讲索引优化的时候说过“var引号不能丢”,如果丢失,会导致索引失效。现在来模拟一下这种情况,上面说过b字段是varchar型,故意把它写错不加单引号。
MySQL底层是做了类型转换的,但是由于“b”列是做了索引的的一列,自动做了类型转换之后导致类型失效,此时在会话1中修改之后,自己自娱自乐了一番,完全不管会话2受得了受不了发生了阻塞。此时执行commit。
这种情况就是一个不小心就是,var没有加引号,导致索引失效,行锁边表锁。
没有索引或者索引失效时,InnoDB 的行锁变表锁
原因:Mysql 的行锁是通过索引实现的!
间隙锁危害
当用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但不存在的记录,叫做“间隙(GAP)”(宁可错杀不可放过,就算中间出现间隙,找不到指定的记录也会锁住),InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(NEXT-KEY)锁。
间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定值范围内的任何数据,在某些场景下这可能会针对性造成很大的危害。
一般而言,为了云计算和大数据分析,数据最最好是连续的。每一个互联网公司的每一条数据都时很珍贵的,业务逻辑层所写的delete方法调用mapper层delete方法并没有从物理上把这条数据给切切实实的干掉。
总结
- 在会话1中执行范围操作并未提交事务;会话2产生阻塞,暂时不能插入;
- 会话1执行commit;会话2阻塞解除。
行锁总结
InnoDB存储引擎由于事先了行级锁定,虽然在锁定机制的的实现方面,所带来的性能损耗可能比表级锁定会要更高一些,但是在整体并发处理能力方面要远远优于MyISAM的表级锁定的。当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势了。
但是,InnoDB的行级锁定同样也有其脆弱的一面,当使用不当的时候,可能会让InnoDB的整体性能表现不仅不能比MyISAM高,甚至可能更差(就像前面说过的行锁可能变表锁)。
行锁分析:
通过检查 InnoDB_row_lock 状态变量来分析系统上的行锁的争夺情况
show status like 'innodb_row_lock%';
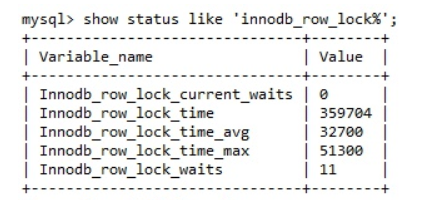
对各个状态量的说明如下:
Innodb_row_lock_current_waits:当前正在等待锁定的数量;
Innodb_row_lock_time:从系统启动到现在锁定总时间长度;
Innodb_row_lock_time_avg:每次等待锁花费平均时间;
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次说话的时间;
Innodb_row_lock_waits :启动系统后到现在总共等待的次数;
对于5个状态变量,比较重要的是:
Innodb_row_lock_time_avg(等待锁的平均时长)
Innodb_row_lock_waits (等待总次数)
Innodb_row_lock_time(等待总时长)
尤其是当等待次数越高,而且每次等待时长也不小的时候,就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手制定优化计划。
优化建议
- 尽可能在所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能较少检索条件,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可能低级别事务隔离
补充:
如何锁定一行?
在SQL语句后面加上for update,直到锁定行的会话提交commit。

3.页锁
开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
MySQL主从复制
概念
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
主要用途
- 读写分离 在开发工作中,有时候会遇见某个sql 语句需要锁表,导致暂时不能使用读的服务,这样就会影响现有业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
- 数据实时备份,当系统中某个节点发生故障时,可以方便的故障切换
- 高可用HA
- 架构扩展 随着系统中业务访问量的增大,如果是单机部署数据库,就会导致I/O访问频率过高。有了主从复制,增加多个数据存储节点,将负载分布在多个从节点上,降低单机磁盘I/O访问的频率,提高单个机器的I/O性能。
基本原理
slave会从master读取binlog来进行数据同步。
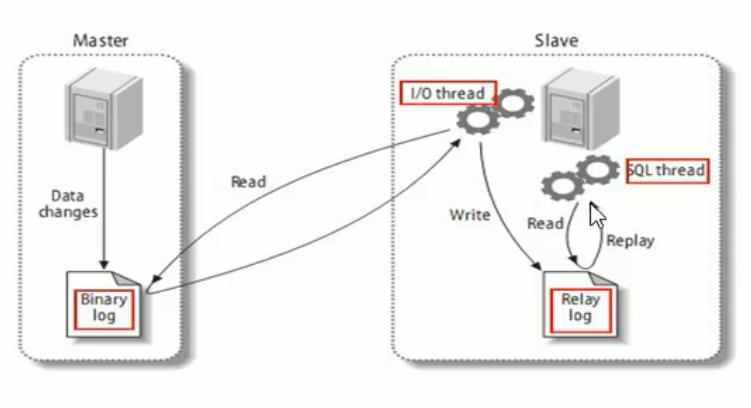
三步:
- master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;
- slave将master的binary log events拷贝到它的中继日志(relay log) ;
- slave重做中继日志中的事件,将改变应用到自己的数据库中。MySQL复制是异步的且串行化的。
基本原则
每个slave只有一个master
每个slave只能有一个唯一的服务器ID
每个master可以有多个salve
复制的最大问题是延迟。